신용 평가 모델링
소개
안녕하세요. 에잇퍼센트 CSS(: Credit Scoring System)팀입니다. 에잇퍼센트는 대출과 투자를 연계하여 대출자에게는 대출의 기회를, 투자자에게는 새로운 투자 상품을 제공하는 8퍼센트 서비스를 제공하고 있습니다. 에잇퍼센트는 대출자의 신용을 평가하여 대출 조건을 결정합니다. 에잇퍼센트 CSS팀은 머신러닝 모델을 활용하여 더 나은 평가를 하기 위해 노력하고 있습니다. 이러한 노력의 시도들을 나누고자 합니다.
신용 평가
신용 평가는 전문성과 객관성을 갖춘 평가기관이 채무자가 만기까지 원리금을 상환할 수 있는 능력을 측정하고 이를 등급으로 나누어 운용하는 체계입니다. 에잇퍼센트 신용평가는 모형, 전략, 그리고 심사자에 의한 심층 심사 과정으로 이루어집니다. 신용평가는 대출의 부실을 예측하기 위한 것이지만, 현실적으로 부실 여부에 대한 판단은 오랜 시간이 소요되므로 연체 여부에 대한 예측으로 갈음하는 것이 보통입니다. 즉, 신용 평가는 분류 문제로 귀결됩니다. 저는 신용 평가 중에서 모형에 대한 이야기를 해보려고 합니다.
Credit Bureau(이하 CB)와 데이터
모형의 학습에는 데이터가 필수입니다. 이는 신용 평가에서도 마찬가지입니다. 신용 평가를 하는 금융 기관은 금융거래정보를 토대로 신용도를 평가하는 기관인 CB의 데이터를 구매하거나 받아서 모델이나 전략을 만듭니다. 최근에는 앱 로그, 마이 데이터 등으로 이루어진 대안 데이터를 활용하기도 합니다.
CB 데이터는 기본 신상 정보, 대출 정보, 연체 정보, 그리고 카드 정보 등을 포함합니다. 그리고 CB가 자체 개발한 지표도 있습니다. CB 데이터의 특징 중 하나로 Special Value를 둔다는 점이 있습니다. 아래의 예시를 봅시다.
| Code | 설명 | Special Value |
|---|---|---|
| ABC001 | 60일 내 카드 한도 소진율 | [SV1] 신용카드기관수<2일 때 8888888.8,[SV2] 60일 내 총한도금액합계=0일 때 9999999.9 |
ABC001라는 변수는 Special Value를 두 가지 두고 있습니다.
첫 번째는 신용카드기관수가 2개 미만인 때로 나와있는데, 신용카드기관수가 없다면 총한도금액합계도 0이 되므로 두 번째 Special Value를 가지게 될 것입니다. 그러므로 신용카드기관수가 1개인 경우에만 해당합니다. 이를 Special Value로 두어 처리하는 이유는, 다른 금융회사가 변수 ABC001를 통해 특정 회사의 카드 정책을 유추할 수 있기 때문입니다.
두 번째는 총한도금액합계가 0일 때로, 나누기 연산 과정에서 분모에 0이 들어가게 되는 문제를 방지하기 위함입니다.
분석 방법론
모델 구축은 다음과 같은 단계로 구성됩니다.
- 변수 선택
- 데이터 전처리
- 모델링
변수 선택
변수 선택 방법은 여러 가지가 있지만, 독립 변수 들과 종속 변수와의 상관관계를 극대화하면서, 독립 변수 들 사이의 관련성은 극소화하는 것을 목표로 하는 mrmr 방법론을 활용하였습니다. (참고: https://github.com/smazzanti/mrmr) 추가적으로 기간의 변화에도 견고한 변수 선택이 이루어질 수 있도록 기간을 임의로 선택하여 변수를 선택하는 시도를 여러 번 하였고, 그 결과 나온 변수 집합 들의 교집합을 선택하였습니다.
데이터 전처리
모형이 제대로 학습할 수 있도록 데이터를 전처리하는 것이 필요합니다. 모형이 제대로 학습할 수 있도록 다음과 같은 데이터 전처리가 필요합니다.
- 변수만 활용하도록 추려내기
- 카테고리 변수를 숫자로 바꾸기
- 누락 데이터(Missing Value) 처리하기
- 날짜 변수 변환하기
Neural Network 기반의 모형에서는 큰 값을 처리할 때 기울기 증폭 등의 문제가 발생할 우려가 있어 Min Max Scaling도 사용하였습니다. Neural Network 기반의 모형에서는 Special Value를 포함한 Feature, 그리고 Categorical Feature에 대한 처리도 하였습니다. Special Value를 포함한 Feature에서는 예를 들어 두 개의 Special Value가 있으면, Special Value에 속하지 않으면 원래 값을 Min Max scaler한 값을 v라고 할 때 (v, 0, 0)으로, SV1에 해당하면 (0, 1, 0)으로 SV2에 해당하면 (0, 0, 1)로 인코딩하도록 하였습니다. Categorical Feature의 경우에는 One Hot Encoding을 활용하였습니다.
모형 소개
신용 평가에서 전통적으로 사용하는 모형은 Logistic Regression입니다. Logistic Regression은 종속 변수가 두 가지 범주로 나뉘는 데이터를 분석하는 경우에 적용하는 확률모델로서, 독립 변수의 선형적 결합으로 종속 변수를 설명하는 회귀 분석에 속합니다. 각각의 독립 변수의 종속 변수에 대한 영향을 선형적으로 파악하기 쉽다는 장점이 있습니다. 하지만 성능 측면에서는 머신 러닝 모형에 비해 낮습니다. 이어서 시도해 본 머신러닝 모형들에 대해 소개드리겠습니다.
Decision Tree
Decision Tree란 Tree구조를 통해 판단을 내리는 모형으로, 어떠한 변수 들의 값을 기준으로 가지를 치게 됩니다. 그리하여 특정 데이터의 예측 값은 루트 노드로부터 각 기준을 거쳐 잎 노드로 이어지는 경로를 통해 구하게 됩니다. 가지를 분할할 때에는 Greedy한 방식으로 Loss를 줄이는 방식으로 분할하게 됩니다. Decision Tree 자체만으로도 모델링을 하긴 하지만, 이를 응용한 Random Forest나 Gradient Boosting을 더 많이 사용합니다.
Random Forest
다수의 Decision Tree를 학습하여 그 예측값의 다수결 혹은 평균값을 활용하는 방식입니다. 각각의 Tree를 학습할 때 랜덤하게 변수들을 선택하여 학습함으로써 각 Tree가 서로 다른 특성을 가지도록 합니다.
Gradient Boosting
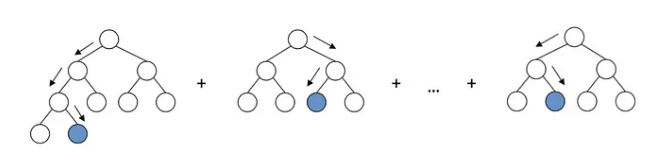
출처: Gradient Boosting explained [demonstration] (arogozhnikov.github.io)
마찬가지로 다수의 Decision Tree를 학습하여 활용하는 Ensemble 학습에 해당합니다. 다만 위의 그림에서 볼 수 있듯이 각 Tree의 예측값의 합을 활용합니다. 학습할 때에는 처음에는 Label을 예측하는 Tree를 만들고, 그 다음에는 생성한 Tree의 예측값과 실제 Label 값과의 잔차를 예측하는 Tree를 만듭니다. 그리고 그 다음에는 앞에서 만든 Tree들의 예측값의 합과 Label 값과의 차이를 예측하는 Tree를 만듭니다. 이러한 방식으로 여러개의 Tree를 학습합니다. Gradient Boosting의 하나의 예로 Extreme Gradient Boost(이하 XGBoost)가 있습니다. XGBoost는 손실 함수의 2차 근사식까지 사용하여 Regularization을 하도록 하는 모형입니다.
Neural Network
Neural Network는 신경망의 구조에 영감을 받아 고안된 모형입니다. 노드 들로 이루어진 층으로 이루어져 있고, 층 간에 가중치를 두어 예측을 하게 됩니다. 가중치는 Back Propagation을 통해 학습을 하게 됩니다. 저희는 Neural Network 기반의 모형 중 Multilayer Perceptron(이하 MLP), Residual Network(이하 ResNet), 그리고 Transformer를 학습해보았습니다.
MLP
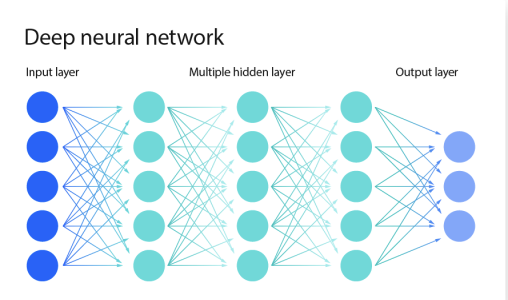
출처: https://engineersplanet.com/35408-2-neural-networks/
Neural Network에서 여러 개의 Hidden Layer를 두어 비선형적인 관계를 설명할 수 있게 만든 모형입니다.
ResNet
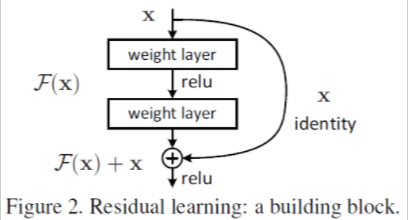
Neural Network 모형에서 깊이가 깊어지면서 Gradient Vanishing 혹은 Exploding의 문제를 해결하기 위해 나타난 구조입니다. 위의 그림에서는 해결 방법인 Skip connection을 보여주는데, output으로 나오는 값에 input 값을 합친 값을 가지고 추론 및 학습을 하게 됨을 알 수 있습니다.
Transformer
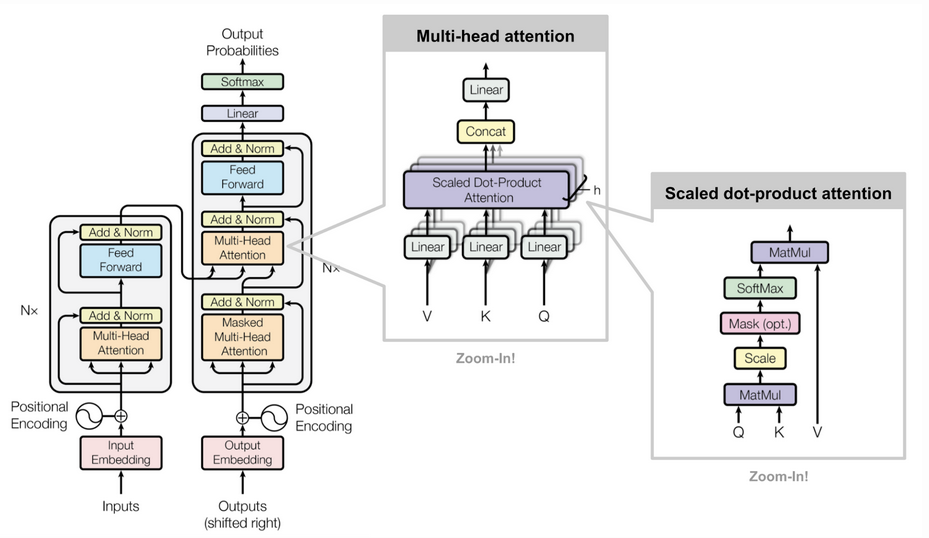
출처: https://github.com/pashu123/Transformers
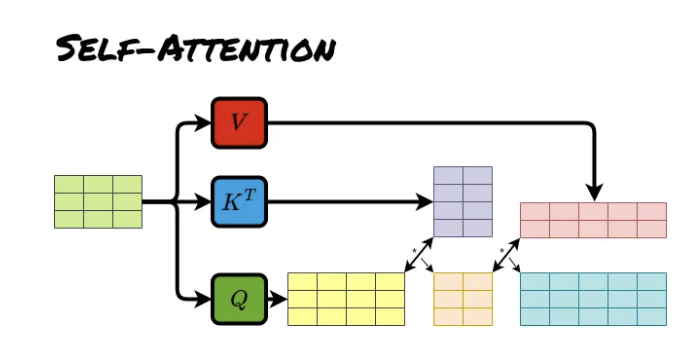
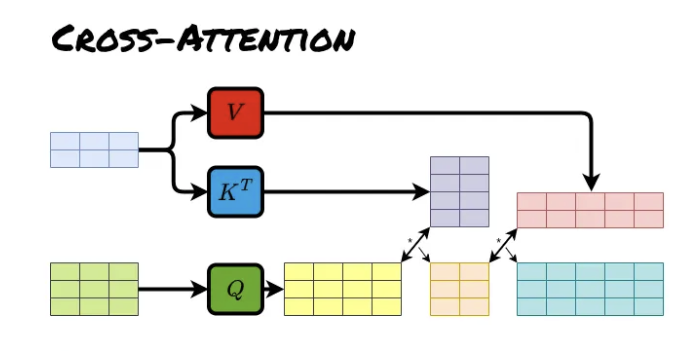
| 출처: [Transformers in Action: Attention Is All You Need | by Soran Ghaderi | Towards Data Science](https://towardsdatascience.com/transformers-in-action-attention-is-all-you-need-ac10338a023a) |
Transformer는 Sequence To Sequence에 해당하는 자연어 처리 분야에서 도입된 모형입니다. 핵심 구조로 input sequence 내에서 각 값들 사이의 영향을 파악하여 어느 부분을 주목해서 예측 할지 판단하기 위한 Self Attention과 input sequence와 output sequence 사이의 영향을 파악하여 예측에 활용하는 Cross Attention이 있습니다.
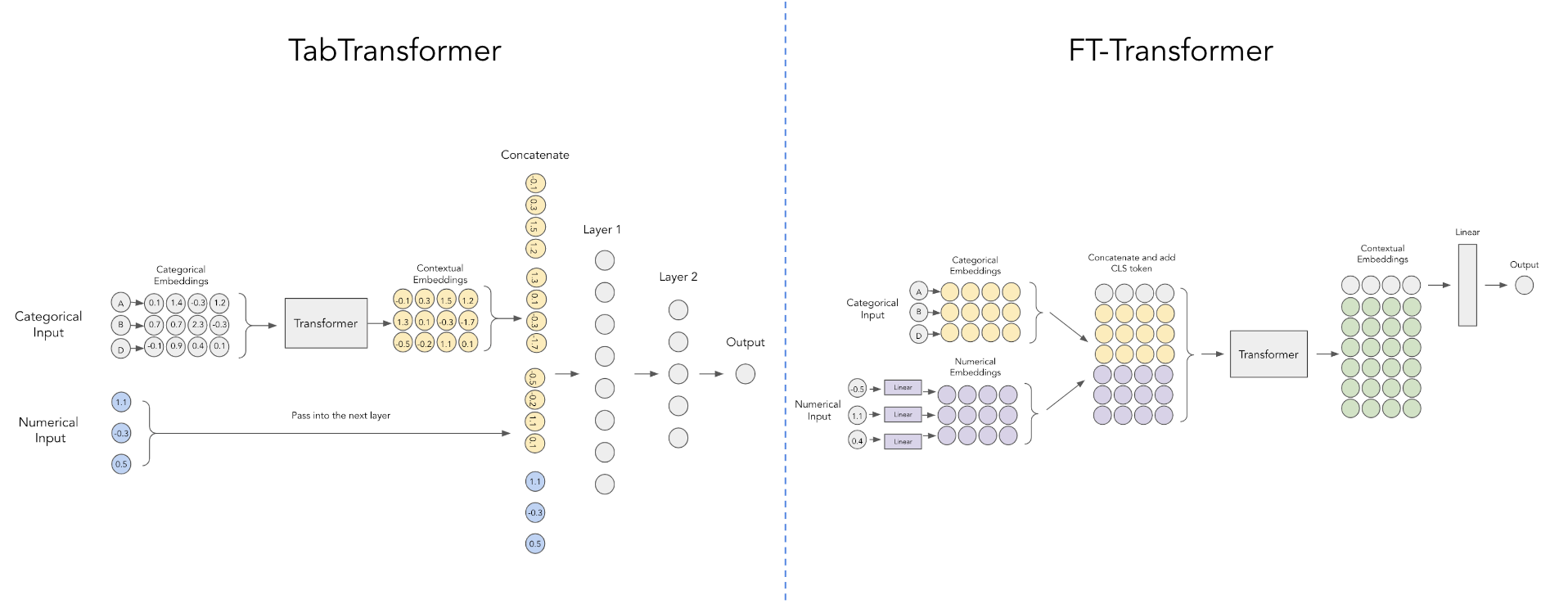
출처: https://github.com/lucidrains/tab-transformer-pytorch/blob/main/tab-vs-ft.png
Transformer를 Classification에 활용할 때에는 output sequence가 없고 label이 있으므로 Cross Attention 대신 MLP를 두었습니다. Transformer를 활용한 Classification의 예시로 TabTransformer와 FT-Transformer를 참고하였는데, 구조는 위와 같습니다. 저희는 FT-Transformer를 참조하되, Special Value가 있는 경우에는 따로 Embedding을 하였고, Transformer를 거친 후에 나온 Embedding의 차원 축소한 뒤 MLP를 거쳐 output을 얻도록 하였습니다.
결과
결과적으로 Neural Network 기반의 모형 중에서는 Transformer를 응용한 모형이 성과가 제일 좋았습니다. 하지만 해당 모형은 XGBoost 보다는 성과가 좋지 않았습니다. Tabular Classification에서 XGBoost가 성능 측면에서 낫다는 설명은 아래의 논문에 자세히 나와있습니다.
참고 논문: Why do tree-based models still outperform deep learning on typical tabular data?
향후 과제
아직까지는 XGBoost 모형이 나을지 모르지만, 계속해서 다양한 아키텍처 들이 연구되고 있습니다. 또한 Large Language Model을 활용하는 시도도 있습니다. 저희는 더 나은 리스크 제어를 위해 끊임없이 연구하고 도전하려고 합니다.